

How to set up auto-discovery of Kubernetes endpoint services in Prometheus
It’s kicking in an open door to state that you need monitoring when having applications running in Kubernetes (K8s). As K8s is becoming more mature and more adopted year after year (and here to stay), it’s only logical that lots of companies have built professional online monitoring and alerting solutions. Others have created excellent Helm charts that easily and swiftly install a K8s namespace with kube-state-metrics, Prometheus, Grafana with dashboards and Alert manager all-ready-to-go.
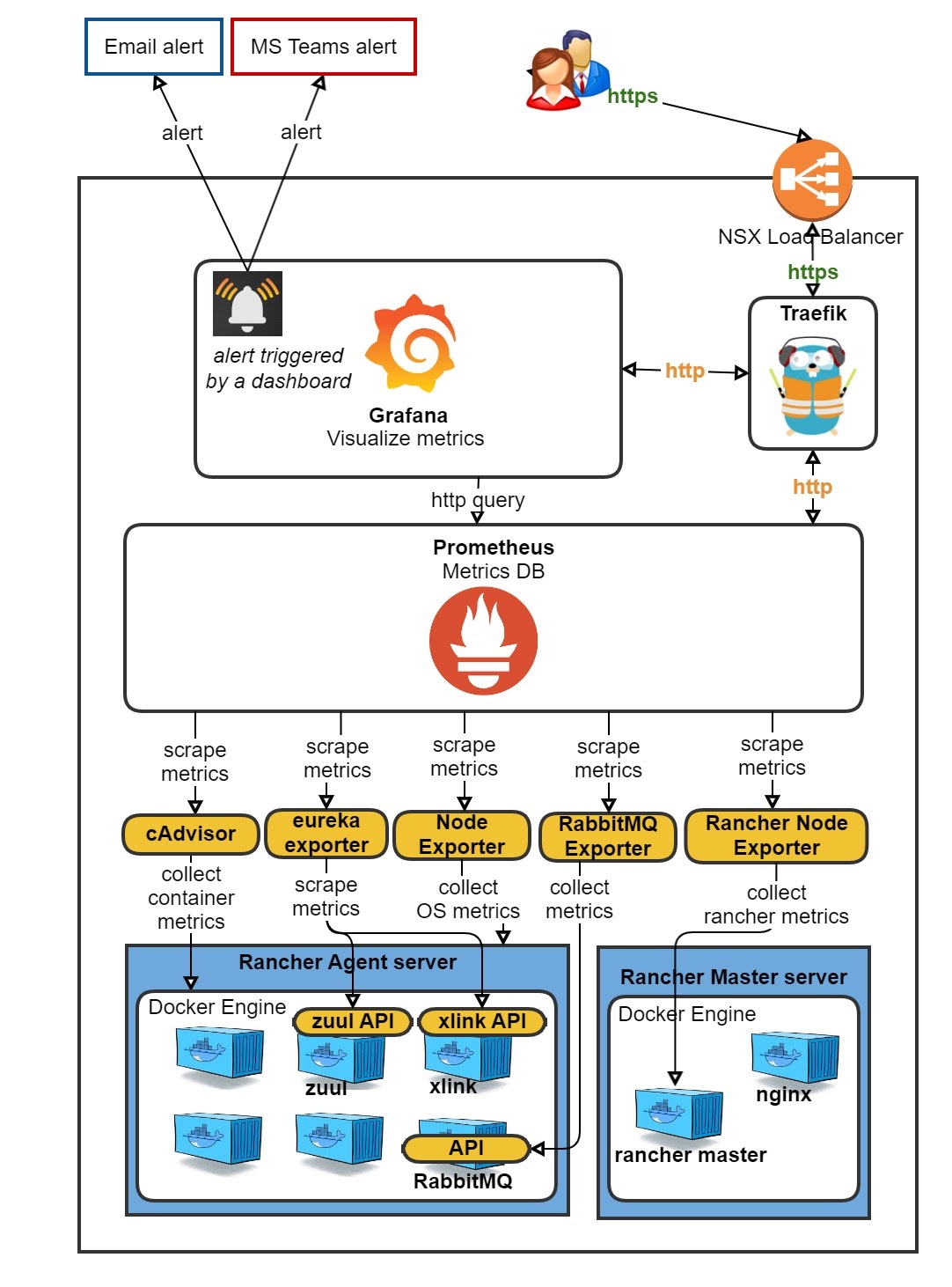
The problem with that is that this is all rather ‘standard’. When you already have a fully customized Prometheus/Grafana setup in Rancher 1, such as we do, it seems a waste to throw this out the window. The journey from a Rancher 1 ‘cattle’ Prometheus/Grafana to Rancher 2 K8s went very smooth and was fairly easy.
However, with Prometheus, you historically would have to edit the prometheus.yaml file every time you want to scrape a new application, unless you had already added your own custom discovery tool as a scrape.
Fixing the incomplete data with auto-discovery
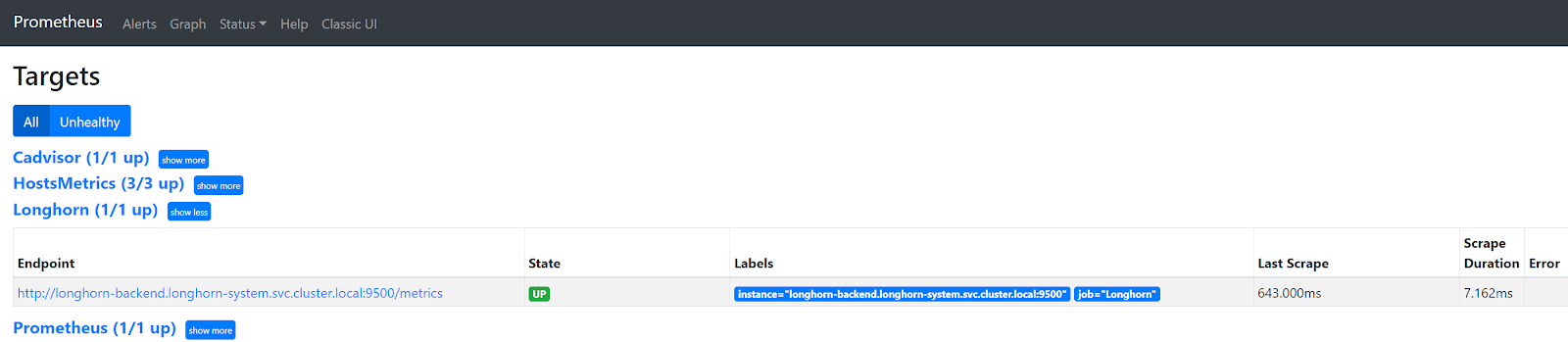
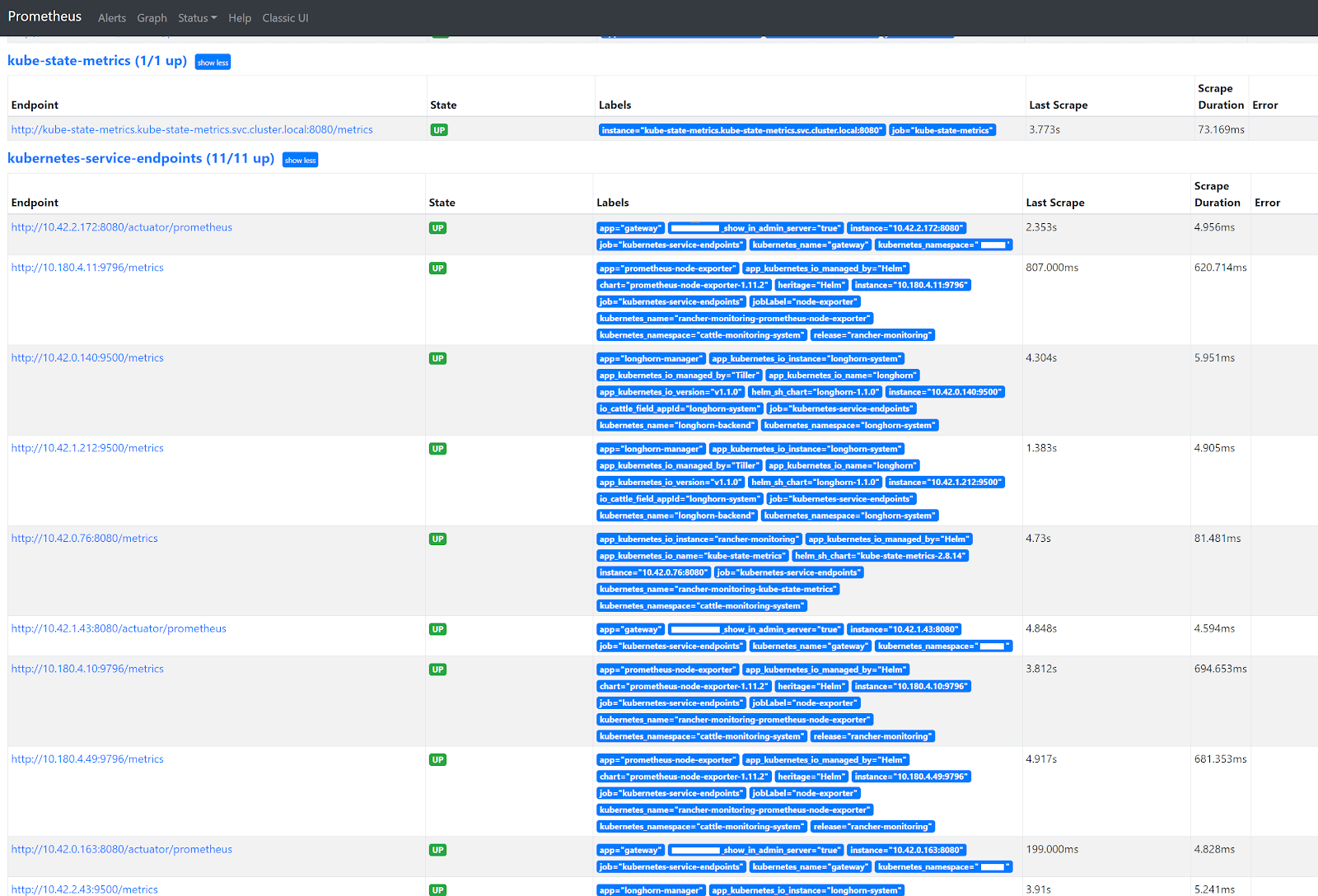
A problem that I faced with directly scraping a Longhorn and Spring Boot (or any other) Service in K8s, is that only one of the many backend pods behind that Service is scraped. So, you end up with incomplete data in Prometheus and hence incomplete data in your dashboards in Grafana. In Prometheus, you can see that only one of three existing Longhorn endpoints is scraped.
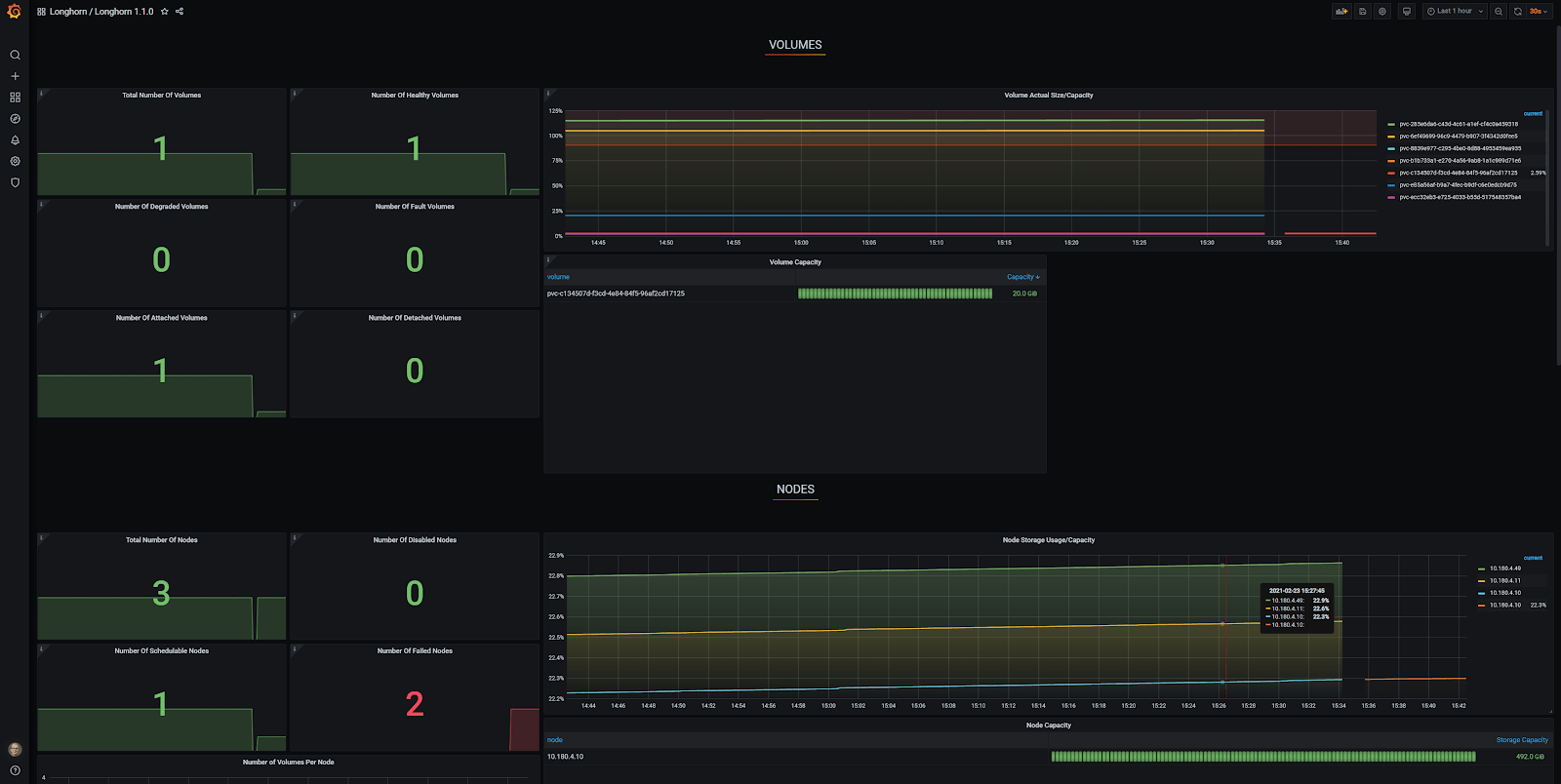
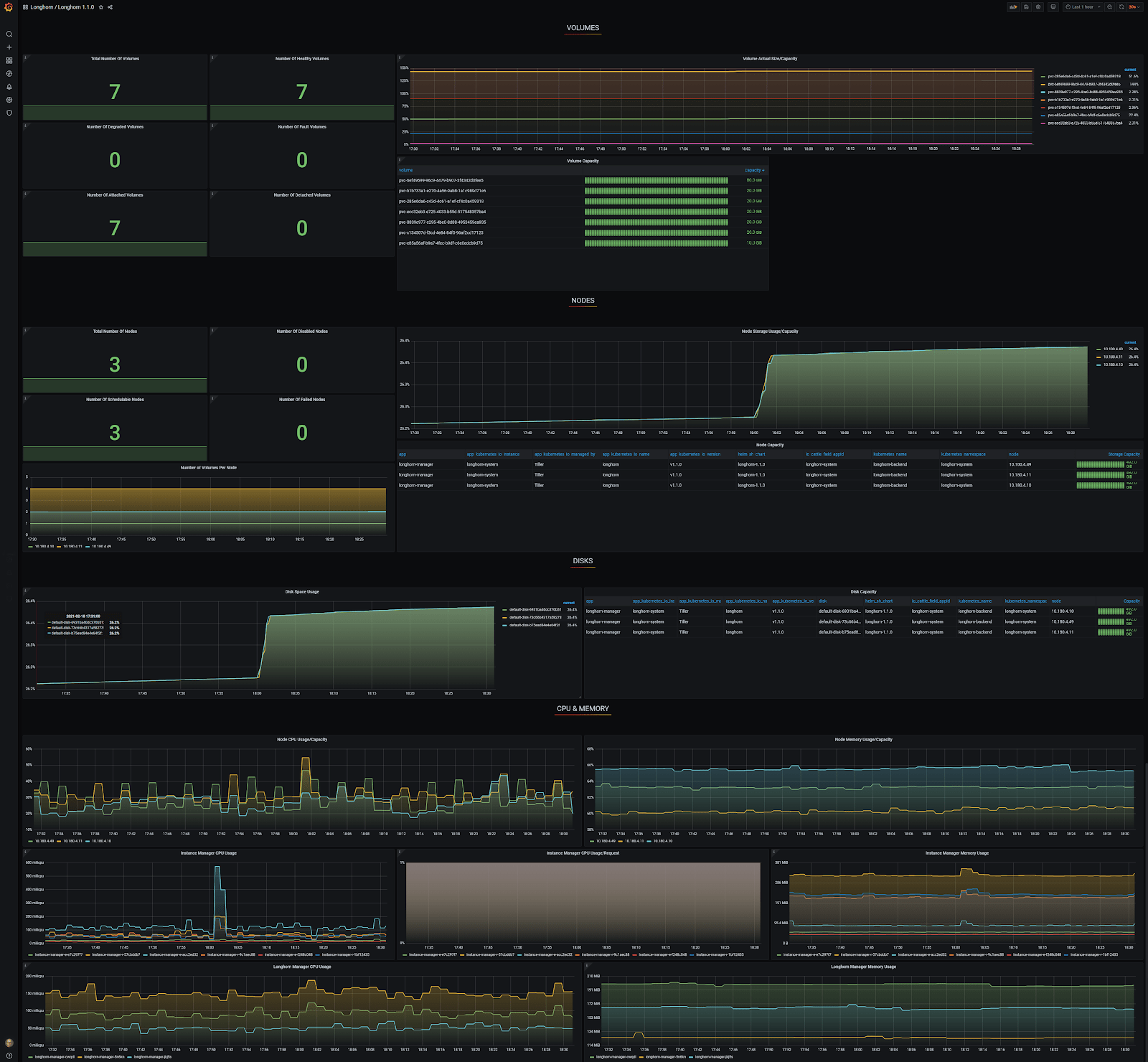
In Grafana, you can see that there is only one node accounted for and the other two are reported as ‘Failed Nodes’. To make matters worse, only one of seven volumes is reported at ‘Total Number of Volumes’.
This is where auto-discovery of Kubernetes endpoint services comes in as a true savior. Many web pages describe the various aspects of scraping, but I found none of them complete and others had critical errors.
In this blog post, I’ll provide you with a minimal and simple configuration to bring your Prometheus configuration with auto-discovery of Kubernetes endpoint services up to speed.
1. Include configMap additions for Prometheus
Add this to the end of the prometheus.yaml in your Prometheus configMap. The jobname is ‘kubernetes-service-endpoints’ as it seemed appropriate.
# Scrape config for service endpoints.
#
# The relabeling allows the actual service scrape endpoint to be configured
# via the following annotations:
#
# * `prometheus.io/scrape`: Only scrape services that have a value of `true`
# * `prometheus.io/scheme`: If the metrics endpoint is secured then you will need
# to set this to `https` & most likely set the `tls_config` of the scrape config.
# * `prometheus.io/path`: If the metrics path is not `/metrics` override this.
# * `prometheus.io/port`: If the metrics are exposed on a different port to the
# service then set this appropriately.
- job_name: 'kubernetes-service-endpoints'
scrape_interval: 5s
scrape_timeout: 2s
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: (.+)(?::\d+);(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name2. Configure the Services
As in the comment above of the prometheus.yaml, you can configure the following annotations. The annotation prometheus.io/scrape: “true” is mandatory, if you want to scrape a particular service. All the other annotations are optional and explained here:
- prometheus.io/scrape: Only scrape services that have a value of `true`
- prometheus.io/scheme: If the metrics endpoint is secured then you will need to set this to `https` & most likely set the `tls_config` of the scrape config.
- prometheus.io/path: If the metrics path is not `/metrics` override this.
- prometheus.io/port: If the metrics are exposed on a different port to the service then set this appropriately.
Let’s look at an example for a Longhorn Service first. (Longhorn is a great replicated storage solution!)
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9500"
prometheus.io/scrape: "true"
labels:
app: longhorn-manager
name: longhorn-backend
namespace: longhorn-system
spec:
ports:
- name: manager
port: 9500
protocol: TCP
targetPort: manager
selector:
app: longhorn-manager
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
type: ClusterIPNext, let’s look at an example for a Spring Boot Application Service. Note the non-standard scrape path /actuator/prometheus.
apiVersion: v1
kind: Service
metadata:
name: springbootapp
namespace: spring
labels:
app: gateway
annotations:
prometheus.io/path: "/actuator/prometheus"
prometheus.io/port: "8080"
prometheus.io/scrape: "true"
spec:
ports:
- name: management
port: 8080
- name: http
port: 80
selector:
app: gateway
sessionAffinity: None
type: ClusterIP3. Configure Prometheus roles
ClusterRole
First, change the namespace as needed. Note: possibly this clusterRole needs to be a little tighter than it currently is.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus
name: prometheus
namespace: prometheus
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- create
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- alertmanagers/finalizers
- prometheuses
- prometheuses/finalizers
- thanosrulers
- thanosrulers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- "*"
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]ClusterRoleBinding
Again, change the namespace as needed.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus
name: prometheus
namespace: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: prometheusServiceAccount
Once more, change the namespace as needed. DO NOT change the name unless you change the ClusterRoleBinding subjects.name as well.
apiVersion: v1
kind: ServiceAccount
metadata:
name: default
namespace: prometheusApply
First, apply the ServiceAccount, ClusterRoleBinding, ClusterRole and Services to your K8s cluster. After updating the Prometheus configMap, redeploy Prometheus to make sure that the new configMap is activated/loaded.
Results in Prometheus
Go to the Prometheus GUI and navigate to Status -> Targets. You’ll see that now all the pod endpoints ‘magically’ pop up at the kubernetes-services-endpoints heading. Any future prometheus.io related annotation changes in k8s Services will immediately come into effect after applying them!
Grafana Longhorn dashboard
I used a generic Grafana Longhorn dashboard, which you can find here for yourself. Thanks to the auto-discovery, the Grafana Longhorn dashboard now correctly shows three nodes and seven volumes, which is exactly correct!
Conclusion
After running through all the steps in this blog post, you basically never have to look at your Prometheus configuration again. With auto-discovery of Kubernetes endpoint services, adding and removing Prometheus scrapes for your applications has now become almost as simple as unlocking your cell phone!
I hope this blog post has helped you out! If you have any questions, reach out to me. Or, if you’d like professional advice and services, see how we can help you out with Kubernetes!










