


Hoe wij een highly-available Altassian stack met Kubernetes hebben gebouwd
Binnen ACA werken meerdere teams op verschillende (of dezelfde!) projecten. Elk team heeft zijn eigen expertisedomein, zoals software op maat, marketing & communicatie, mobile development en meer. De teams gespecialiseerd in Atlassian producten en cloud-expertise hebben hun kennis gebundeld om een highly-available Atlassian stack op Kubernetes te creëren. Zo konden we niet enkel onze interne processen verbeteren, maar ook onze klanten deze oplossing aanbieden!
In deze blogpost leggen we uit hoe onze Atlassian en cloud teams een highly-available
Atlassian stack bovenop Kubernetes hebben gebouwd. Naast de voordelen van deze aanpak, bespreken we ook de problemen die we zijn tegengekomen. Als laatste bespreken we hoe we deze opzet monitoren.
De setup van onze Atlassian stack
Onze Atlassian stack bestaat uit de volgende producten:
- Amazon EKS
- Amazon EFS
- Atlassian Jira Data Center
- Atlassian Confluence Data Center
- Amazon EBS
- Atlassian Bitbucket Data Center
- Amazon RDS
Zoals je ziet gebruiken we AWS als cloud provider voor onze Kubernetes setup. We maken alle resources aan met behulp van Terraform. De afbeelding hieronder geeft je een algemene
indruk:
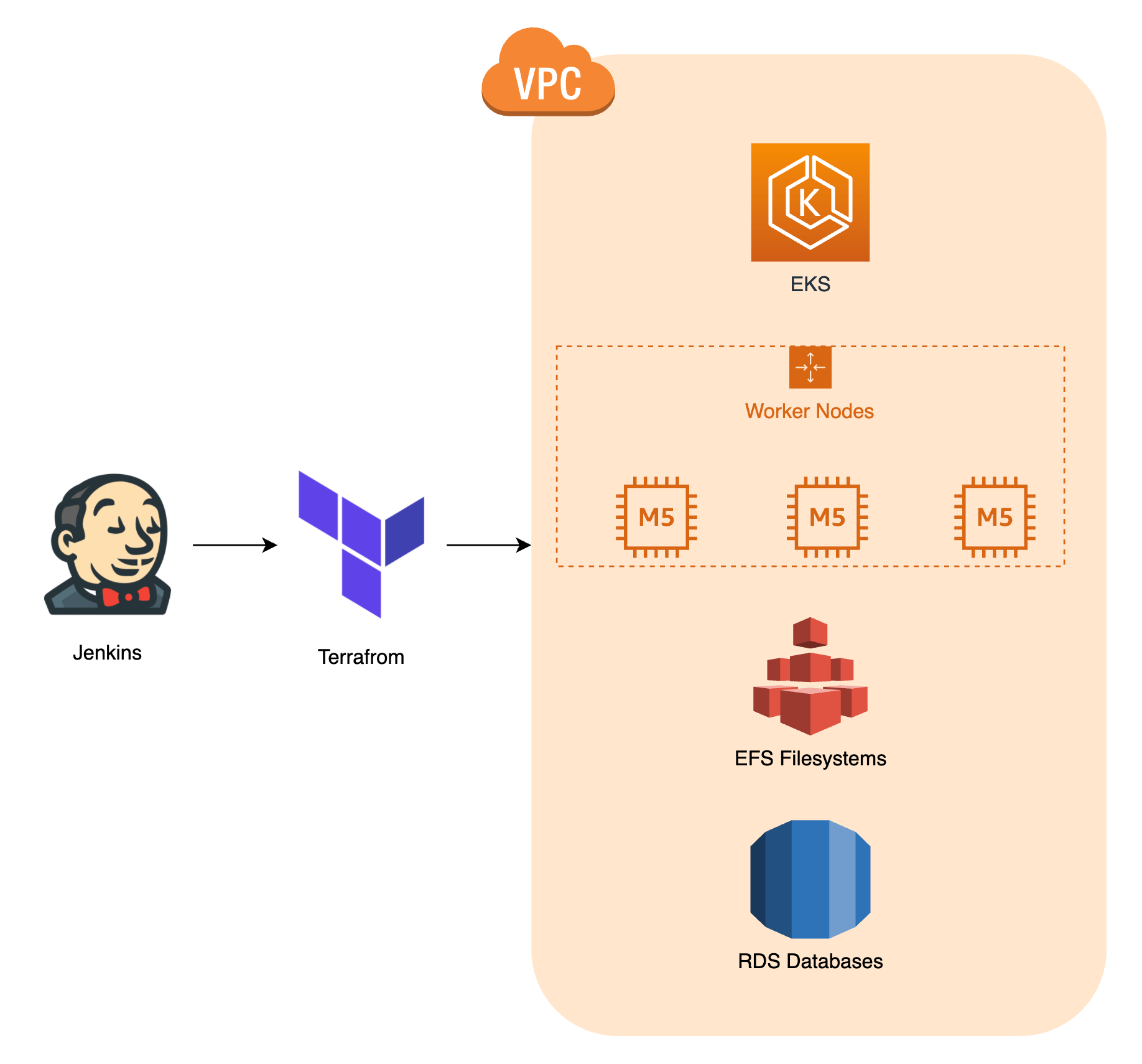
Onderstaand diagram geeft je een idee van onze setup van ons Atlassian Data Center.
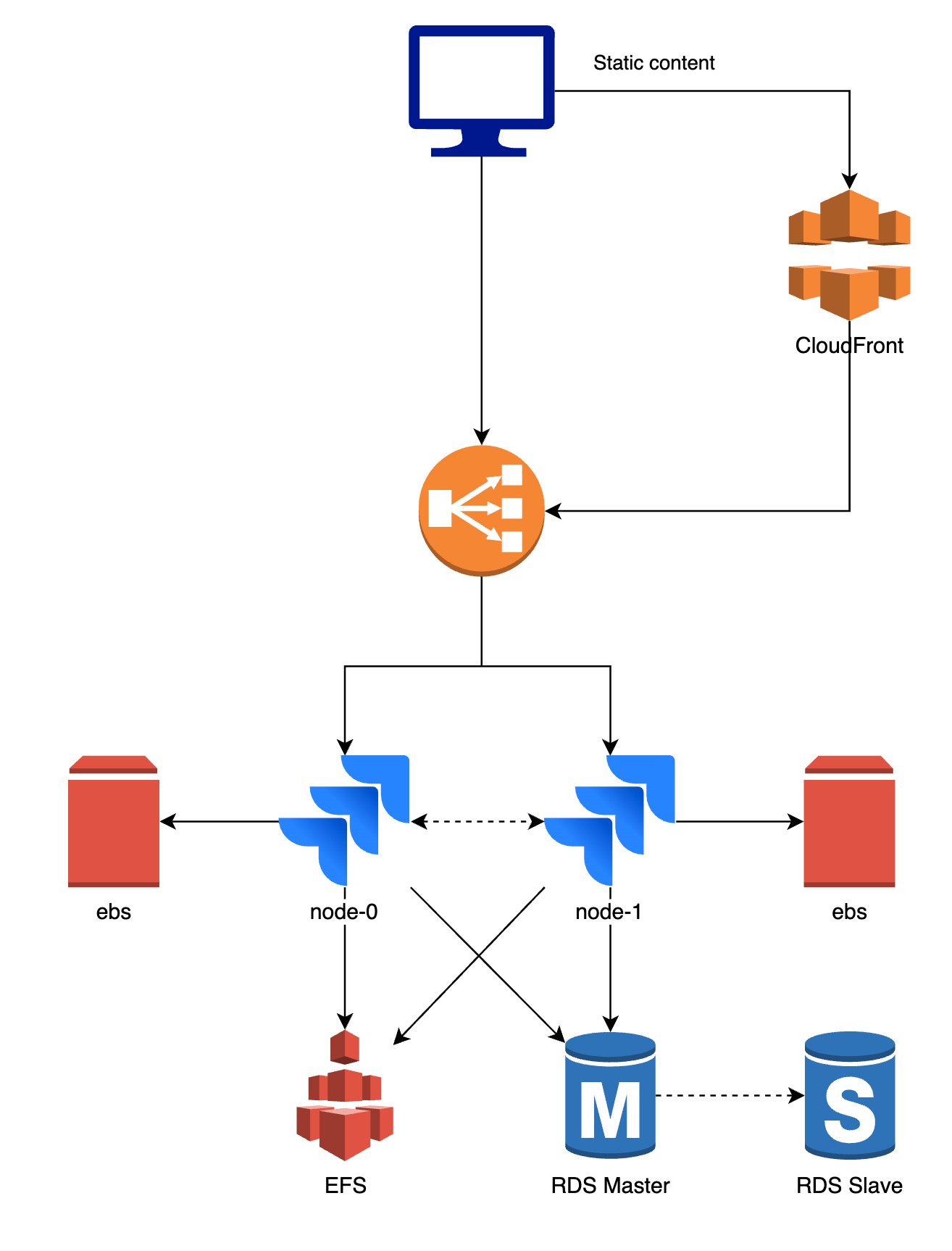
Hoewel er een paar verschillen zijn tussen de producten en opzet, blijft het in de kern
hetzelfde.
- De applicatie wordt gelanceerd als één of meerdere pods die worden beschreven door een StatefulSet. Deze pods npemen we node-0 en node-1 in het diagram hierboven.
- Het eerste verzoek wordt verzonden naar de load balancer en doorgestuurd naar ofwel de node-0 of node-1 pod. Het verkeer is moeizaam, dus alle navolgende verkeer van die gebruiker zal verzonden worden naar node-1.
- Zowel pod-0 als pod-1 hebben persistente opslag nodig die gebruikt wordt voor de plugin cache en indexatie. Aan elk van de pods is een ander Amazon EBS-volume gekoppeld.
- Bijna alle gegevens zoals jouw JIRA issues, Confluence spaces, ... worden opgeslagen in een database. Deze database wordt gedeeld: node-0 en node-1 maken beide verbinding met dezelfde database. Wij gebruiken meestal PostgreSQL en Amazon RDS.
- De node-0 en node-1 pod moeten bovendien grote bestanden delen, zoals bijvoorbeeld bijlagen, die we niet willen opslaan in een database. Hetzelfde Amazon EFS volume is geïnstalleerd op beide pods. Wanneer er aanpassingen gebeuren, bijvoorbeeld een bijlage werd geupload aan een issue, zijn deze onmiddellijk beschikbaar op beide pods.
- We gebruiken CloudFront (CDN) om statische objecten in de cache op te slaan en de web response tijd te verbeteren.
De voordelen van deze setup
Door deze opzet te gebruiken, kunnen we niet alleen de voordelen van Docker en Kubernetes benutten, maar ook die van de Data Center versies van de Atlassian tooling. Er zijn heel wat voordelen verbonden aan deze setup, maar we lijsten de belangrijkste even op:
- Het is een self-healing platform: containers en worker nodes vervangen zichzelf automatisch als er een defect optreedt. In de meeste gevallen hoeven we niets te doen en lost de stack het probleem zelf op. Uiteraard is het belangrijk om oorzaak van deze defecten te achterhalen zodat deze in de toekomst vermeden kunnen worden.
- Exact nul downtime deployments: bij het upgraden naar een nieuwe versie van de eerste node binnen de cluster kunnen we onze klanten nog steeds de oude versie bieden op de tweede node. Zodra de upgrade is voltooid, is de nieuwe versie beschikbaar vanaf de eerste node en kunnen we de tweede node upgraden. Op deze manier blijft de applicatie stabiel, zelfs tijdens upgrades.
- Deployments zijn voorspelbaar: we gebruiken dezelfde Docker container voor
ontwikkeling, staging en productie. Daarom zijn wij ervan overtuigd dat de container kan starten in onze productieomgeving na een succesvolle inzet naar staging. - Beschikbaarheid van applicaties: wanneer een van de nodes uitvalt, vangt de andere nodige het "verkeer" op. Op deze manier heb je tijd om het issue na te kijken en de defecte node te herstellen terwijl de applicatie gewoon beschikbaar blijft voor de gebruiker.
- Het is mogelijk om data van de een naar de andere node te synchroniseren. Je kan bijvoorbeeld in slechts enkele seconden tijd de index van de ene naar de andere node overzetten om een beschadigde index te herstellen. Het volledig opnieuw indexeren zou veel meer tijd in beslag nemen.
- Je kunt op alle lagen een hoog beveiligingsniveau implementeren (AWS, Kubernetes, applicatie, ...)
- AWS CloudTrail beschermt tegen ongeautoriseerde toegang op AWS en stuurt een waarschuwing in geval van afwijkingen.
- AWS Config beschermt AWS security group aanpassingen. Je vindt meer terug over hoe jouw cloud beschermen met AWS Config in onze blogpost.
- Terraform zorgt ervoor dat aanpassingen op het AWS landschap voor de uitrol ervan worden goedgekeurd door het team.
- Aangezien het upgraden van Kubernetes master en worker nodes zo goed als geen invloed hebben, draait de stack steeds op een recente versie met de laatste beveiligingspatches.
- We gebruiken een combinatie van namespacing en RBAC om te verzekeren dat applicaties en deployments enkel toegang hebben tot de bronnen binnen hun namespace met de laagst mogelijke rechten.
- NetworkPolicies worden uitgerold met Calico. We weigeren standaard al het verkeer tussen containers en laten enkel specifiek verkeer toe.
- We gebruiken recente versies van de Atlassian applicaties en implementeren Security Advisories wanneer deze worden gepubliceerd door Atlassian.
- AWS CloudTrail beschermt tegen ongeautoriseerde toegang op AWS en stuurt een waarschuwing in geval van afwijkingen.

Interesse om de kracht van Kubernetes zelf te benutten? Je vindt meer informatie over hoe wij jou kunnen helpen terug op onze website!











