


Apache Kafka in a nutshell
Apache Kafka is a highly flexible streaming platform. It focuses on scalable, real-time data pipelines that are persistent and very performant. But how does it work, and what do you use it for?
How does Apache Kafka work?
For a long time, applications were built using a database where ‘things’ are stored. Those things can be an order, a person, a car … and the database stores them with a certain state.

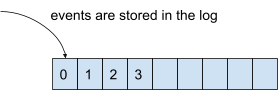
Unlike this approach, Kafka doesn’t think in terms of ‘things’ but in terms of ‘events’. An event has also a state, but it is something that happened in an indication of time. However, it’s a bit cumbersome to store events in a database. Therefore, Kafka uses a log: an ordered sequence of events that’s also durable.
Decoupling
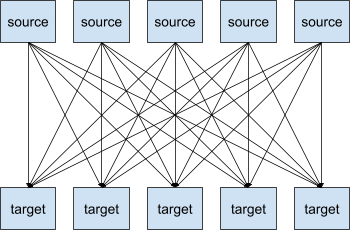
If you have a system with different source systems and target systems, you want to integrate them with each other. These integrations can be tedious because they have their own protocols, different data formats, different data structures, etc.
So within a system of 5 source and 5 target systems, you’ll likely have to write 25 integrations. It can become very complicated very quickly.
And this is where Kafka comes in. With Kafka, the above integration scheme looks like this:
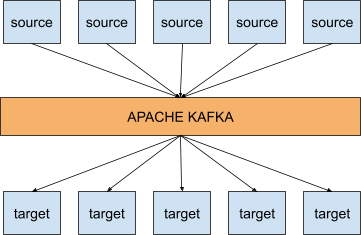
So what does that mean? It means that Kafka helps you to decouple your data streams. Source systems only have to publish their events to Kafka, and target systems consume the events from Kafka. On top of the decoupling, Apache Kafka is also very scalable, has a resilient architecture, is fault-tolerant, is distributed and is highly performant.
Topics and partitions
A topic is a particular stream of data and is identified by a name. Topics consist of partitions. Each message in a partition is ordered and gets an incremental ID called an offset. An offset only has a meaning within a specific partition.
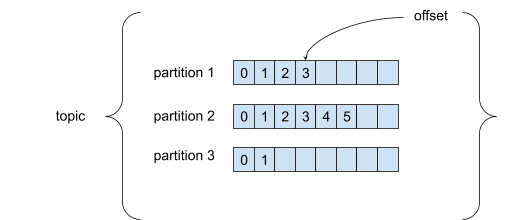
Within a partition, the order of the messages is guaranteed. But when you send a message to a topic, it is randomly assigned to a partition. So if you want to keep the order of certain messages, you’ll need to give the messages a key. A message with a key is always assigned to the same partition.
Messages are also immutable. If you need to change them, you’ll have to send an extra ‘update-message’.
Brokers
A Kafka cluster is composed of different brokers. Each broker is assigned an ID, and each broker contains certain partitions. When you connect to a broker in the cluster, you’re automatically connected to the whole cluster.
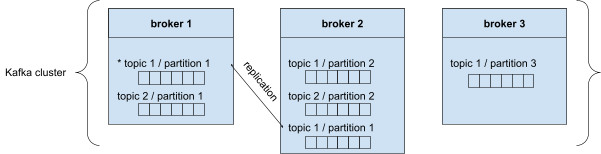
As you can see in the illustration above, topic 1/partition 1 is replicated in broker 2. Only one broker can be a leader for a topic/partition. In this example, broker 1 is the leader and broker 2 will automatically sync the replicated topic/partitions. This is what we call an ‘in sync replica’ (ISR).
Producers
A producer sends the messages to the Kafka cluster to write them to a specific topic. Therefore, the producer must know the topic name and one broker. We already established that you automatically connect to the entire cluster when connecting to a broker. Kafka takes care of the routing to the correct broker.
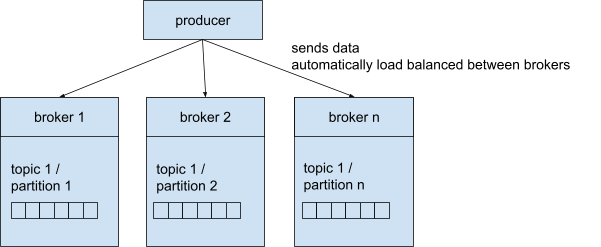
A producer can be configured to get an acknowledgement (ACK) of the data write:
ACK=0: producer will not wait for acknowledgement
ACK=1: producer will wait for the leader broker’s acknowledgement
ACK=ALL: producer will wait for the leader broker’s and replica broker’s acknowledgement
Obviously, a higher ACK is much safer and guarantees no data loss. On the other hand, it’s less performant.
Consumers
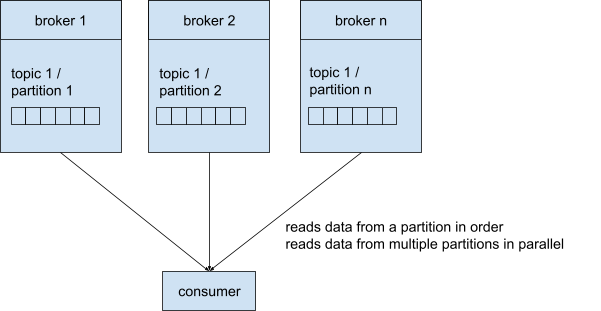
A consumer reads data from a topic. Therefore, the consumer must know the topic name and one broker. Like the producers, when connecting to one broker, you’re connected to the whole cluster. Again, Kafka takes care of the routing to the correct broker.
Consumers read the messages from a partition in order, taking the offset into account. If consumers read from multiple partitions, they read them in parallel.
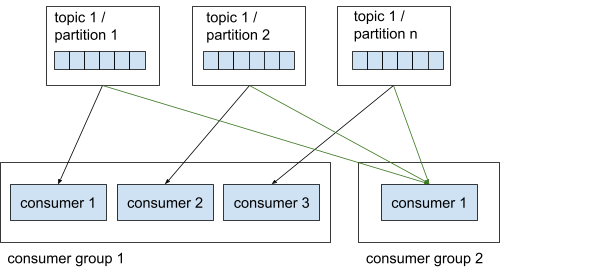
Consumer groups
Consumers are organized into groups, i.e. consumer groups. These groups are useful to enhance parallelism. Within a consumer group, each consumer reads from an exclusive partition. This means that, in consumer group 1, both consumer 1 and consumer 2 cannot read from the same partition. A consumer group can also not have more consumers than partitions, because some consumers will not have a partition to read from.
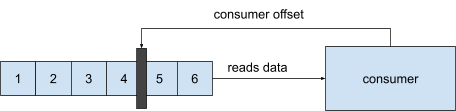
Consumer offset
When a consumer reads a message from the partition, it commits the offset every time. In the case of a consumer dying or network issues, the consumer knows where to continue when it’s back online.
Why we don't use a message queue
There are some differences between Kafka and a message queue. Some main differences are that after a consumer of a message queue receives a message, it’s removed from the queue, while Kafka doesn’t remove the messages/events.
This allows you to have multiple consumers on a topic that can read the same messages, but execute different logic on them. Since the messages are persistent, you can also replay them. When you have multiple consumers on a message queue, they generally apply the same logic to the messages and are only useful to handle load.
Use cases for Apache Kafka
There are many use cases for Kafka. Let’s look at some examples.
Parcel delivery telemetry
When you order something on a web shop, you’ll probably get a notification from the courier service with a tracking link. In some cases, you can actually follow the driver in real-time on a map. This is where Kafka comes in: the courier’s van has a GPS built in that sends its coordinates regularly to a Kafka cluster. The website you’re looking at listens to those events and shows you the courier’s exact position on a map in real-time.
Website activity tracking
Kafka can be used for tracking and capturing website activity. Events such as page views, user searches, etc. are captured in Kafka topics. This data is then used for a range of use cases like real-time monitoring, real-time processing or even loading this data into a data lake for further offline processing and reporting.
Application health monitoring
Servers can be monitored and set to trigger alarms in case of system faults. Information from servers can be combined with the server syslogs and sent to a Kafka cluster. Through Kafka, these topics can be joined and set to trigger alarms based on usage thresholds, containing full information for easier troubleshooting of system problems before they become catastrophic.
Conclusion
In this blog post, we’ve broadly explained how Apache Kafka works, and for what this incredible platform can be used. We hope you learned something new! If you have any questions, please let us know. Thanks for reading!









